研究内容
人間は音声を通じて自身の考えや感情、意図などを相手に伝えることができます。音声言語研究室は、コンピュータが人間のように、音声から誰が・どこで・どんな感情・意図で・何を話しているか、といった様々な情報を理解したり、またこれらの様々な情報を反映した音声を作り出したりする技術の実現を目指しています。さらに、対象を音声から音全体に広げて、環境音を分析することで異常検出や安全監視を行う技術や、音楽の理解や生成といった技術も研究しています。またこれらの技術を応用して、例えば障がい者支援のための音声入力インタフェースなど、安心・安全な社会の実現に資する技術の開発も目指しています。
音声認識
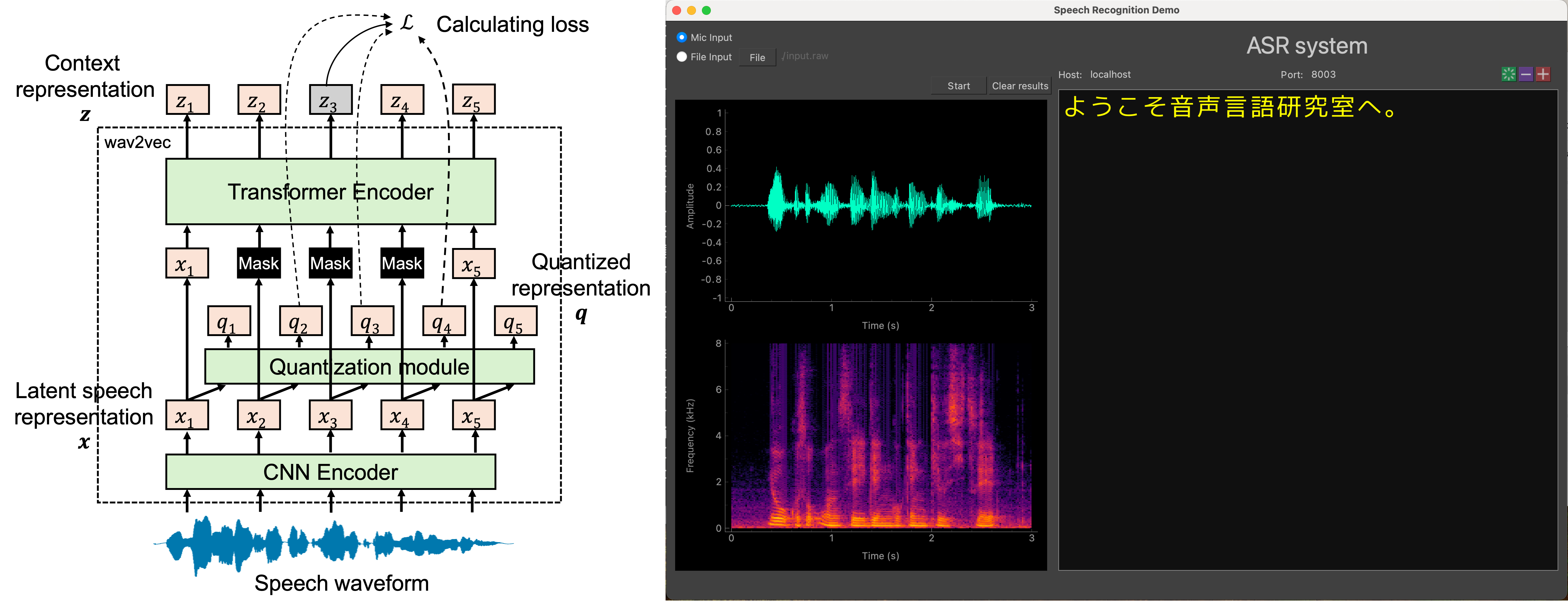
コンピュータに入力された音声から、発話内容を認識する技術です。現在の音声認識技術は大量の学習データが存在する音声については高精度に認識が可能ですが、一部の言語や構音障がいのある音声のような、学習データの乏しい音声の認識は困難です。研究室ではこのようなマイノリティ音声の認識に取り組みます。
音声感情認識
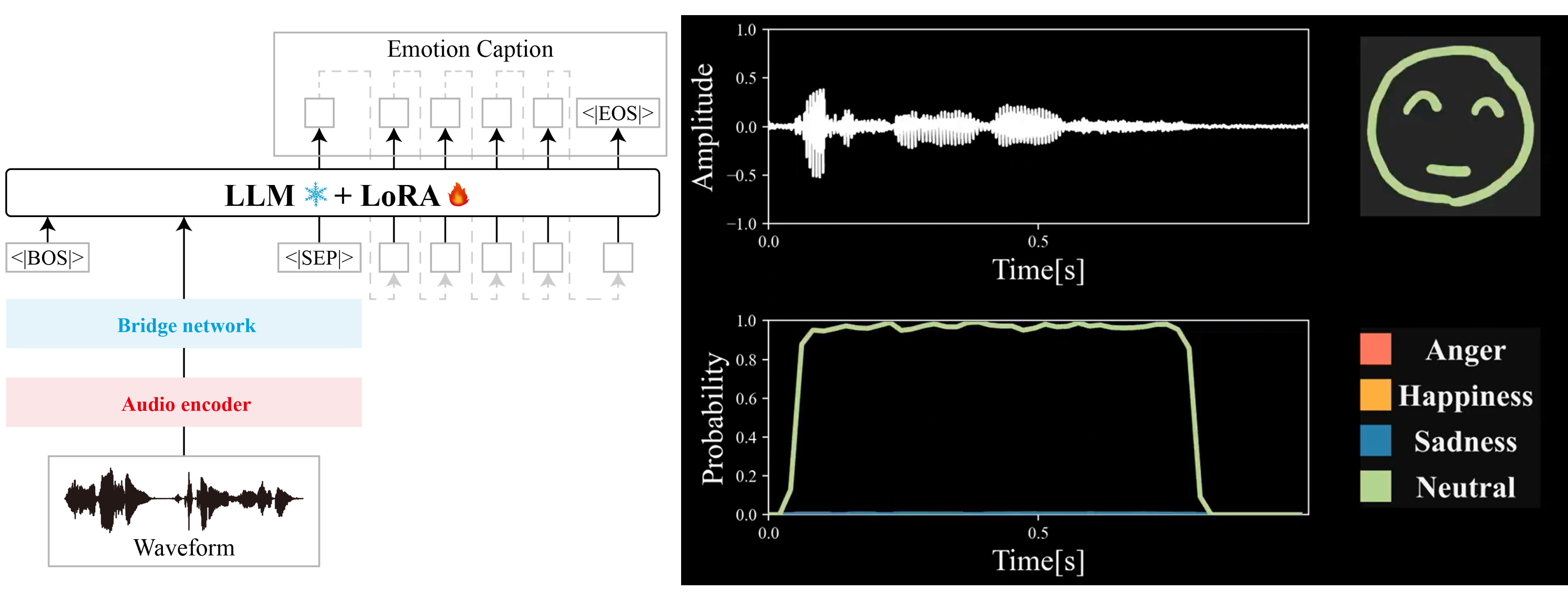
声の高さや声色などの音響情報や発話内容などの言語情報から感情をコンピュータで推定する技術です。この技術は、対話型ロボットにおけるユーザの感情理解やコールセンター業務の応対支援などに応用されています。研究室では、時々刻々と変化する感情を音声からリアルタイムで認識する手法や、「怒り」や「喜び」などの感情だけでなく「特別感を感じ嬉しくなっている」のような詳しい感情を音声から認識する手法の研究に取り組んでいます。
音声合成・声質変換
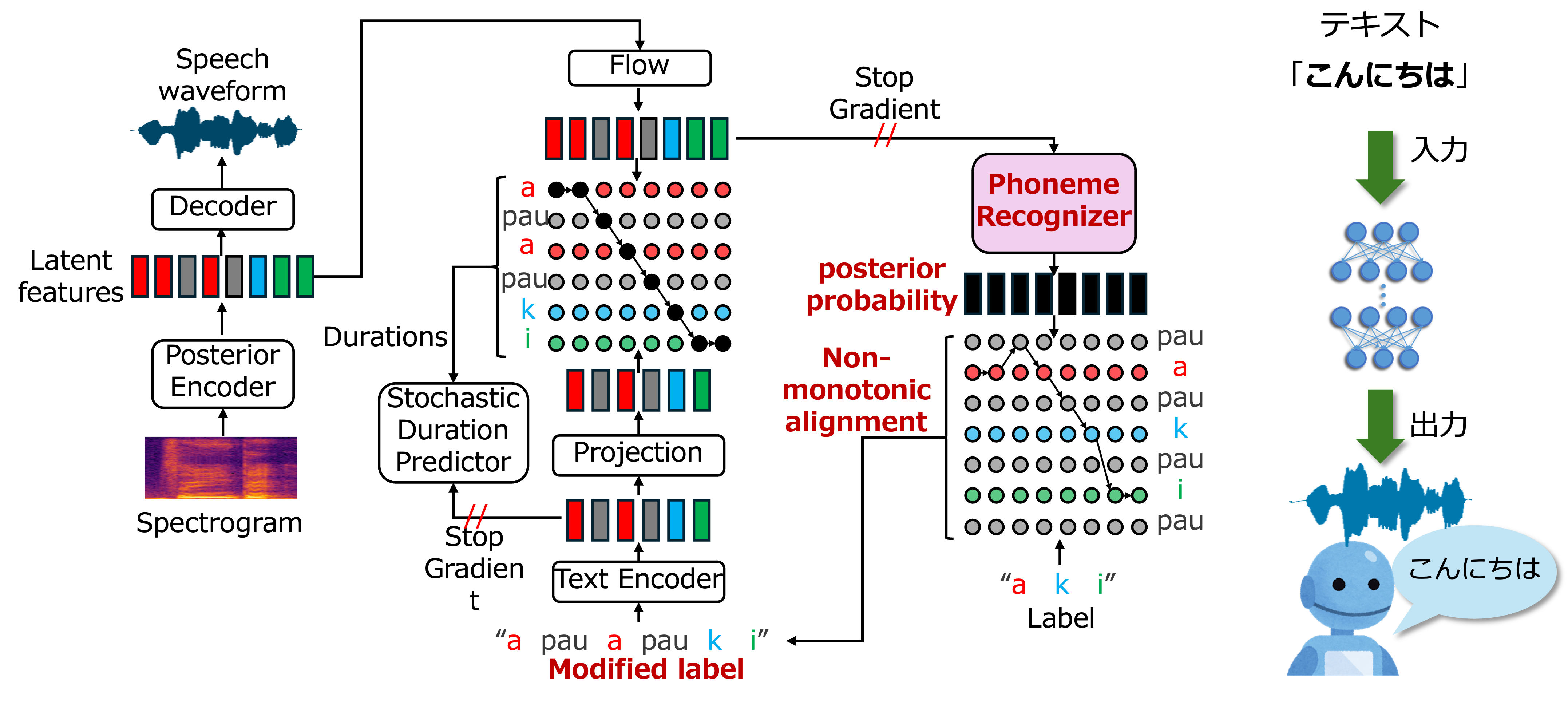
音声合成は、コンピュータに入力されたテキストから音声を生成する技術です。声質変換は、入力された音声の声質を別人のものに変換する技術です。研究室では、発話内容や声質の再現だけでなく、感情や細かな発話スタイルまで再現する、より人間らしい音声の生成を目指します。
環境音認識
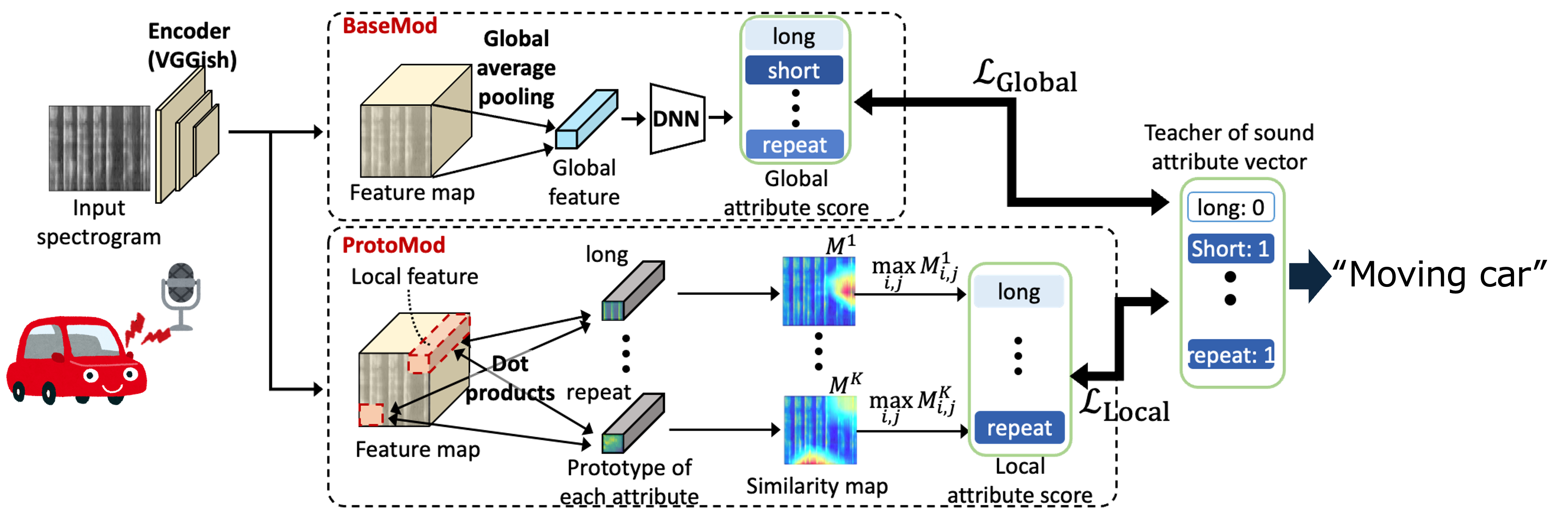
収録音を分析することで、車の走行音や水の流れる音というように、それが何によって発生している音なのかを認識する技術です。環境音認識は異常検知や幼児・高齢者の見守りへの応用が期待されていますが、異常事態は滅多に起こらないため、異常音を認識するための学習データ不足の問題があります。研究室ではこの問題を解決するために、学習データが少量、あるいはゼロの環境音を認識する研究に取り組みます。
音楽分析・生成
音楽分析は、入力された音楽について、使用されている楽器やメロディ、リズムなどを分析する技術です。音楽生成は、演奏方法や直前のメロディなどの情報から楽曲を生成する技術です。研究室では、音楽から演奏者の感情を分析したり、直前と直後のメロディを入力するとその間のメロディを補完する技術の研究に取り組んでいます。
